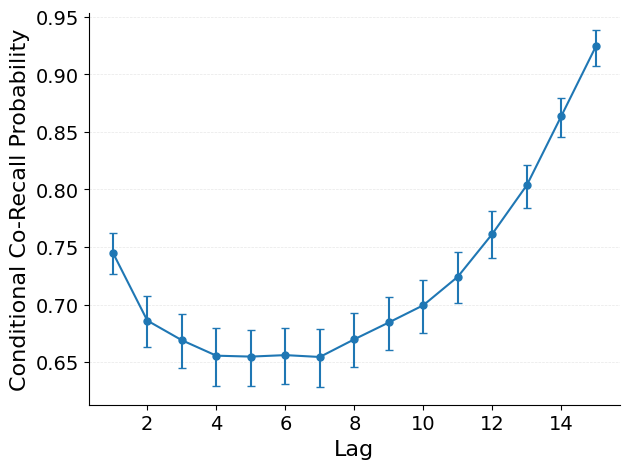
Measure how nearby study positions cluster in recall, conditioned on anchor recall.
Conditional co-recall by lag measures the probability that a neighbor \(d\) positions away in the study list was recalled, given that the anchor position was recalled, ignoring recall order. For each recalled anchor at position \(i\), we check whether the item at position \(i + d\) was also recalled on the same trial.
\[\text{CoRec}(d) = \frac{\sum_t \text{co-recalled pairs at lag } d}{\sum_t \text{recalled anchors available at lag } d}\]
Unlike joint co-recall, conditioning on the anchor being recalled removes the baseline recall rate, isolating the associative clustering between nearby study positions.
The x-axis shows study lag and the y-axis shows the conditional probability that the neighbor was also recalled. Key patterns:
Peak near lag 1: items studied immediately after the anchor are most likely to be co-recalled, reflecting associative clustering.
Decline with lag: co-recall probability drops with increasing study distance.
Comparison with joint co-recall: conditional co-recall removes baseline recall rate, providing a cleaner measure of associative strength.
API Details### Notebook parameters- data_path — path to an HDF5 file containing a RecallDataset.- figure_dir — directory for saving figures.- figure_str — base filename for the saved figure. Leave empty to display without saving.- ylim — y-axis limits as a tuple, or None for automatic scaling.- trial_query — a Python expression evaluated against the dataset to select trials.- max_lag — maximum lag to display, or None to use all available lags.- confidence_level — confidence level for subject-wise error bars.To compare across datasets, re-run with different data_path and trial_query values. For example, LohnasKahana2014.h5 uses trial_query = "data['list_type'] == 1" while HealeyKahana2014.h5 uses trial_query = "data['listtype'] == -1".